Eager to join the modern era, I grabbed Jekyll 4.2.2, and a nice theme called
“Basically Basic”; but then the tweaking
began. Looking at the existing blog posts, it was clear that the code blocks and images would need
some work. Because the blog was originally built on pre-3.0
Octopress, I went there to get the original plugins for
code blocks and images.
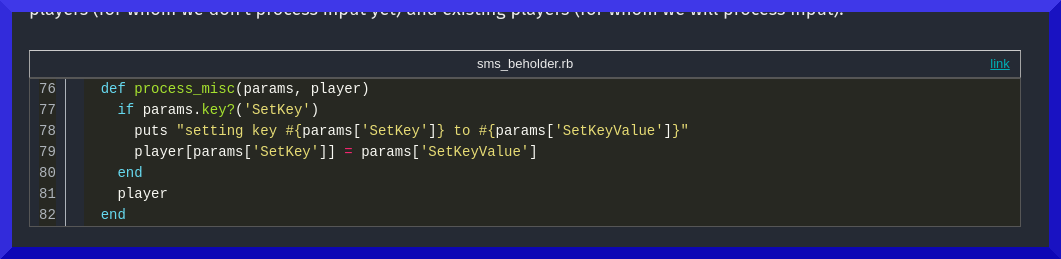
Unfortunately
Jekyll 4 no longer supports Pygments
for syntax highlighting, so I had to convert the code block plugin to use
Rouge in order to format it in the same way. Rouge is
mostly compatible with Pygments-based post-processing, but the line numbering doesn’t quite match
up when you want something like arbitrary beginning line numbers (which I parse out of the link
URL and handle myself, as you can see below).
# Fork of "Simple Code Blocks for Jekyll" https://github.com/imathis/octopress/blob/master/plugins/code_block.rbrequire'./_plugins/rouge_code'require'./_plugins/raw'moduleJekyllclassCodeBlock<Liquid::BlockCaptionUrlTitle=/(\S[\S\s]*)\s+(https?:\/\/\S+|\/\S+)\s*(.+)?/iCaptionUrlTitleNew=/(\S[\S\s]*)\s+<a[\S\s]*>(https?:\/\/\S+|\/\S+)<\/a>\s*(.+)?/iCaption=/(\S[\S\s]*)/definitialize(tag_name,markup,tokens)@title=nil@caption=nil@filetype=nil@starting_line=1@highlight=trueifmarkup=~/\s*lang:(\S+)/i# puts "We found language #{$1}"@filetype=$1markup=markup.sub(/\s*lang:(\S+)/i,'')end# puts "Checking #{markup} against #{CaptionUrlTitle}..."before=Time.nowifmarkup.index('<a href').nil?&&markup=~CaptionUrlTitle# if markup =~ CaptionUrlTitle# puts "We found CaptionUrlTitle file #{$1} code_url #{$2} linktext #{$3}"@file=$1code_url=$2@caption="<figcaption><span>#{$1}</span><a href='#{$2}'>#{$3||'link'}</a></figcaption>"ifcode_url=~/\S+#L(\d+)/@starting_line=$1.to_iendelsifmarkup=~Caption# puts "We found Caption file #{$1}"@file=$1@caption="<figcaption><span>#{$1}</span></figcaption>\n"end# puts "...that took #{Time.now - before} seconds."if@file=~/\S[\S\s]*\w+\.(\w+)/&&@filetype.nil?# puts "We found filetype #{$1}"@filetype=$1end# puts "...done"superenddefrender(context)output=supercode=supercode_lines=code.lines# code_lines.each_with_index do |line,index|# puts "raw code line #{index}, with #{line.length} chars, is \"#{line}\""# if line.length < 20# puts " Dumped, it's #{line.dump}"# end# endifcode_lines[0]=="\n"||code_lines[0]=="\r\n"code_lines.shiftendifcode_lines.last=="\n"||code_lines.last=="\r\n"code_lines.popend# code_lines.each_with_index do |line,index|# puts "less raw code line #{index}, with #{line.length} chars, is \"#{line}\""# if line.length < 20# puts " Dumped, it's #{line.dump}"# end# endcode=code_lines.joinsource="<figure class='code'>"source+=@captionif@captionif@filetypesource+="#{HighlightCode::highlight(code,@filetype,@starting_line)}</figure>"elsesource+="#{HighlightCode::tableize_code(code.lstrip.rstrip.gsub(/</,'<'))}</figure>"endsource=TemplateWrapper::safe_wrap(source)source=context['pygments_prefix']+sourceifcontext['pygments_prefix']source=source+context['pygments_suffix']ifcontext['pygments_suffix']sourceendendendLiquid::Template.register_tag('codeblock',Jekyll::CodeBlock)
# Conversion of https://github.com/imathis/octopress/blob/master/plugins/pygments_code.rb for use# with Rouge 3.x.require'fileutils'require'digest/md5'# ROUGE_CACHE_DIR = File.expand_path('../../.rouge-cache', __FILE__)# FileUtils.mkdir_p(ROUGE_CACHE_DIR)moduleHighlightCodedefself.highlight(str,lang,starting_line=1)lang='ruby'iflang=='ru'lang='objc'iflang=='m'lang='perl'iflang=='pl'lang='yaml'iflang=='yml'str=rouge(str,lang)tableize_code(str,lang,starting_line)enddefself.rouge(code,lang)require"rouge"formatter=::Rouge::Formatters::HTML.newformatter=::Rouge::Formatters::HTMLLinewise.new(formatter,{class:"highlight"})lexer=::Rouge::Lexer.find_fancy(lang,code)||Rouge::Lexers::PlainTextifdefined?(ROUGE_CACHE_DIR)path=File.join(ROUGE_CACHE_DIR,"#{lang}-#{Digest::MD5.hexdigest(code)}.html")ifFile.exist?(path)highlighted_code=File.read(path)elsebeginhighlighted_code=formatter.format(lexer.lex(code))endFile.open(path,'w'){|f|f.print(highlighted_code)}endelsehighlighted_code=formatter.format(lexer.lex(code))endhighlighted_codeenddefself.tableize_code(str,lang='',starting_line=1)table='<div class="highlight"><table><tr><td class="gutter"><pre class="line-numbers">'code=''str.lines.each_with_indexdo|line,index|# puts "code line #{index} is #{line}"# now get rid of those div tagsline=line.delete_prefix("</div>")line=line.delete_prefix("<div class=\"highlight\">")line=line.tr("\r",'')iflang=='json'# getting extra carriage returns from JSON for some reason.# the last line is likely blank nowifindex==str.lines.length-1&&line==""# puts " ...skipping that one."nextendtable+="<span class='line-number'>#{index+starting_line}</span>\n"code+="<span class='line'>#{line}</span>"endtable+="</pre></td><td class='code'><pre><code class='#{lang}'>#{code}</code></pre></td></tr></table></div>"endend
There’s a lot of “printf debugging” in there (commented out at the moment); it took a lot of trial
and error to get the formatting I expected. The caching proved to have no impact at all in this
environment, so I disabled it so it wouldn’t be a concern. It took
a bit of CSS work
as well, and the code blocks look a bit better to me now:
Not perfect, but better.
The image tag code and CSS from Octopress worked well, without much trouble.
I started considering how I would handle the categories, and add some less-minimal navigation.
Given the time that had elapsed, I also looked into what newer (but not too new) static site
generators existed. And then I saw
Hugo-Octopress.