
In which we (maybe) finish playing with something almost, but not entirely, unlike wave function collapse.
But First… #
The only thing better than writing code is deleting code.
At this point, the ESTM function is just XSTM with a neighbor distance of 1. Some of the other
functions combine easily as well, letting me remove 300+ lines from wfcish.go. It’s good to go
through and consolidate occasionally, especially when looking at future refactors that might impact
many call sites.
Two Optimizations #
Restructure the Rules #
Previously, we’d been using a “list of rules” structure:
|
|
But the way we tend to look up these rules is by the tile (HomeGraphic above), then offset, to
see what neighbor graphics are allowed. So we shift the structure to align to that pattern:
|
|
Then deriving the ruleset becomes pretty straightforward:
|
|
And so is applying those rules:
|
|
How’s that help us?
$ time go run cmd/xstm/main.go --mapname Annwn --maplevel 4 --method xstm4 -neighbor-distance 4 --max-retries 0 --seed 0 --max-seed 1000 --seek-valid --cpuprofile cpu4.prof
...
FAILED to collapse map.
real 0m44.555s
user 0m54.697s
sys 0m2.177s
$ go tool pprof -http=localhost:1415 cpu4.prof
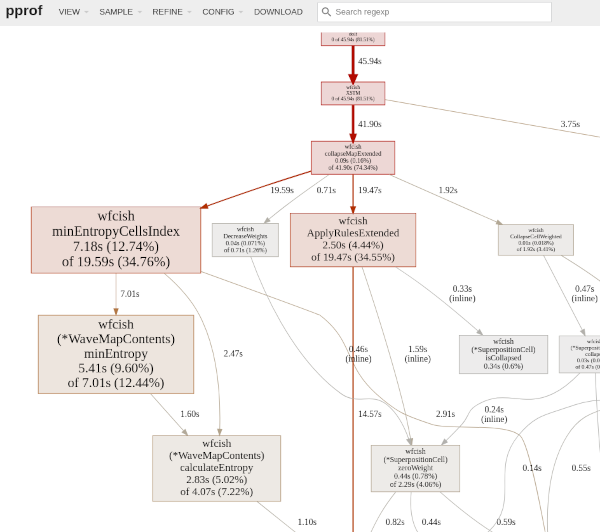
Better, and may enable further optimizations later on.
A Few Small Bits of Concurrency #
So far we’ve been tweaking and optimizing for a single thread of execution (garbage collection aside). Since concurrency is one of the primary features of the Go language, we should probably get around to using it.
Protect the globals #
Since floating-point math takes time, we’ve been caching the results of math.Log2() calls used in
the entropy calculations. It’s always integer weights coming in, so we have slices of float64
indexed by those integers; one for math.Log2(float64(i)) and one for
float64(i)*math.Log2(float64(i)).
If we
want multiple calculations to happen concurrently, we’ll need to make sure these global structures
are protected. How often do we need to expand that cache? After a tiny bit of instrumentation:
$ go run cmd/xstm/main.go --mapname Annwn --maplevel 4 --method xstm4 -neighbor-distance 4 --max-retries 0 --seed 0 --max-seed 2000 --seek-original
...
FAILED to collapse map.
log2cache: Cache hits: 21026036, misses: 3
nlog2ncache: Cache hits: 125213093, misses: 2
Expecting many many more reads than writes, we’ll use a sync.RWMutex lock:
|
|
We’ll take a read lock before looking at the cache. If it turns out we need to extend the cache (i.e. we haven’t yet seen a value this high), we’ll drop it and take a read-write lock before mutating the cache. (Note that we check a second time, since some other call could have extended the cache between us dropping the read lock and picking up the read-write lock.)
|
|
Update All Entropies Concurrently #
Now that we’ve protected those caches, we can launch a set of goroutines to update all of the cell entropies that have become invalid:
|
|
(Note that we only take on the overhead of the goroutines if there are more than 10 cells to update; a rule of thumb we’d want to revisit in any further optimizations.)
The only real difference in the “async” CalculateEntropy() function is a call the waitgroup’s
Done() when it exits, and the lack of a return value:
|
|
Any Better? #
Ok, so now we can split up the relatively expensive entropy calculations among our CPU cores; does that improve things, and if so, how do we examine the details of the improvement?
First, some XSTM benchmarks:
$ git checkout main
$ go test -bench ^Benchmark_ -run XXX gitlab.com/301days/glitch-aura-djinn/pkg/wfcish
goos: linux
goarch: amd64
pkg: gitlab.com/301days/glitch-aura-djinn/pkg/wfcish
cpu: AMD Ryzen 5 3600X 6-Core Processor
Benchmark_XSTM1-12 766 2600697 ns/op
Benchmark_XSTM2-12 300 5012752 ns/op
Benchmark_XSTM3-12 237 5145435 ns/op
Benchmark_XSTM4-12 208 5620292 ns/op
PASS
ok gitlab.com/301days/glitch-aura-djinn/pkg/wfcish 7.563s
$ git checkout concurrency0
$ go test -bench ^Benchmark_ -run XXX gitlab.com/301days/glitch-aura-djinn/pkg/wfcish
goos: linux
goarch: amd64
pkg: gitlab.com/301days/glitch-aura-djinn/pkg/wfcish
cpu: AMD Ryzen 5 3600X 6-Core Processor
Benchmark_XSTM1-12 648 2706977 ns/op
Benchmark_XSTM2-12 225 5795243 ns/op
Benchmark_XSTM3-12 288 4470520 ns/op
Benchmark_XSTM4-12 237 4994846 ns/op
PASS
ok gitlab.com/301days/glitch-aura-djinn/pkg/wfcish 7.174s
A mixed bag, as it were; slower when we’re ignoring the tile frequencies, then a bit faster. Makes sense since we’ve put some effort behind optimizing the entropy calculations.
Now let’s look closely at the differences when running XSTM4, using the tile weights and making sure that an equivalent number of each tile are in the result:
$ git checkout main
$ time go run cmd/xstm/main.go --mapname Annwn --maplevel 4 --method xstm4 -neighbor-distance 4 \
--max-retries 0 --seed 0 --max-seed 2000 --seek-original --cpuprofile main.prof
...
FAILED to collapse map.
real 1m45.859s
user 2m9.076s
sys 0m4.732s
$ git checkout concurrency0
$ time go run cmd/xstm/main.go --mapname Annwn --maplevel 4 --method xstm4 -neighbor-distance 4 \
--max-retries 0 --seed 0 --max-seed 2000 --seek-original --cpuprofile concurrency0.prof
...
FAILED to collapse map.
real 1m28.382s
user 2m20.320s
sys 0m8.192s
$ go tool pprof -http=localhost:1415 -diff_base=main.prof concurrency0.prof
Serving web UI on http://localhost:1415
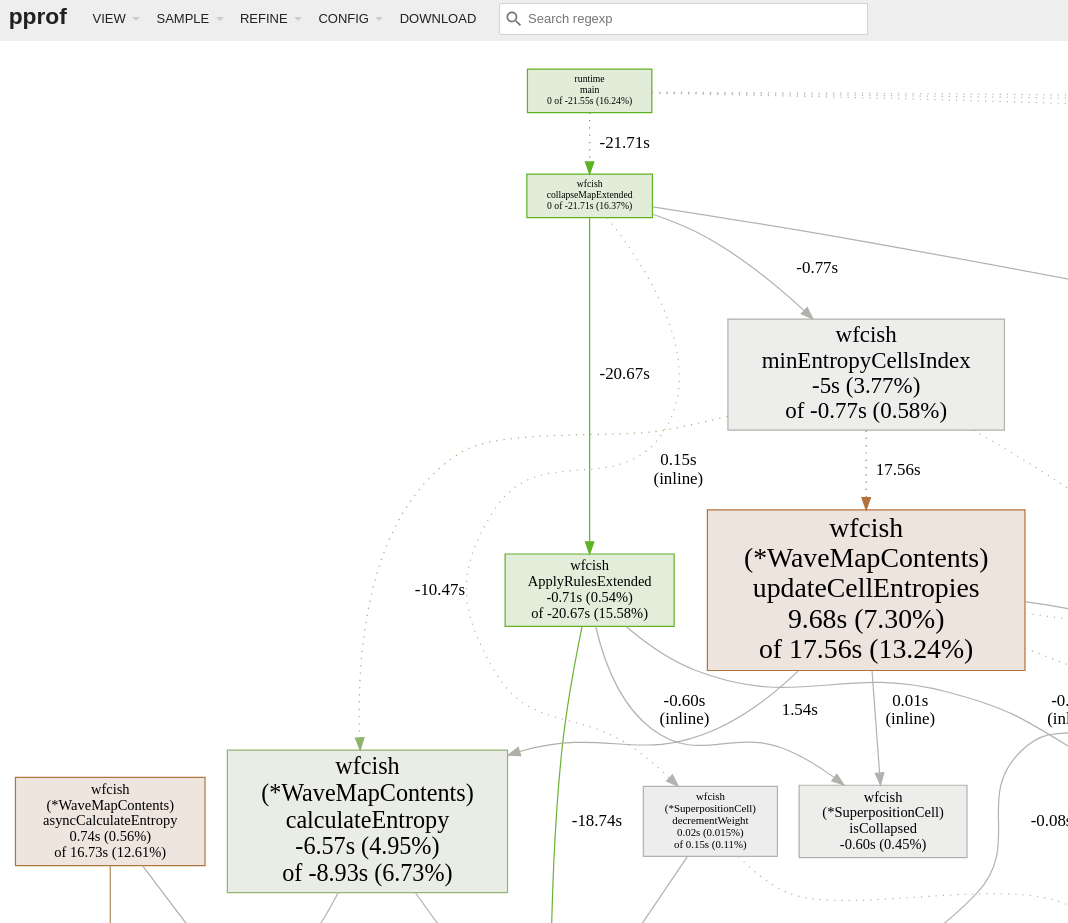
Hmm. minEntropyCellsIndex() is faster now, but ApplyRulesExtended() is much faster. So far,
aligning the rules structure with its usage provided more benefit than concurrently calculating
the cell entropy. Very instructive.
One More Thing… #

Sometimes it’s when we refactor or optimize that we notice simple logical errors that we’ve made earlier. In adding some concurrency to the cell entropy calculations, it’s important to look at what structures those calculations depend upon.
|
|
In a previous optimization, we introduced this TypicalCell to keep track of the tile weights in
one place (and decrease them as tiles are used in XSTM4). But when decreasing those weights, we
don’t invalidate the cells’ entropy cache unless one of the tile weights has dropped to zero:
|
|
So let’s fix that, invalidating the entropy cache of all affected tiles:
|
|
Let’s use some benchmarking to check the effect:
$ go test -bench ^Benchmark_ -run XXX gitlab.com/301days/glitch-aura-djinn/pkg/wfcish \
-benchtime 60s -max-level-size 100
goos: linux
goarch: amd64
pkg: gitlab.com/301days/glitch-aura-djinn/pkg/wfcish
cpu: AMD Ryzen 5 3600X 6-Core Processor
Benchmark_XSTM1-12 36015 2026882 ns/op
Benchmark_XSTM2-12 18231 3941250 ns/op
Benchmark_XSTM3-12 18088 4034165 ns/op
Benchmark_XSTM4BadCache-12 17599 4063649 ns/op
Benchmark_XSTM4GoodCache-12 17288 4174782 ns/op
PASS
ok gitlab.com/301days/glitch-aura-djinn/pkg/wfcish 545.287s
Not too bad, but those are small maps (under 100 characters). How does it look if we include some larger maps?
$ go test -bench ^Benchmark_ -run XXX gitlab.com/301days/glitch-aura-djinn/pkg/wfcish \
-benchtime 60s -max-level-size 1000
goos: linux
goarch: amd64
pkg: gitlab.com/301days/glitch-aura-djinn/pkg/wfcish
cpu: AMD Ryzen 5 3600X 6-Core Processor
Benchmark_XSTM1-12 237 299239987 ns/op
Benchmark_XSTM2-12 225 317676325 ns/op
Benchmark_XSTM3-12 219 328860283 ns/op
Benchmark_XSTM4BadCache-12 222 323149607 ns/op
Benchmark_XSTM4GoodCache-12 68 1027748103 ns/op
PASS
ok gitlab.com/301days/glitch-aura-djinn/pkg/wfcish 485.632s
Oh dear.
